GraphSchema – User Guide
IMPORTANT – It's assumed that you have already read the following article about motivations and overview:
Using Schema in Graph Databases such as Neo4j
Why use a Schema Layer?
"The marriage of the flexibity of Graph Databases and the discipline of Relational Databases"
- Data integrity
- Data filtering upon import
- Assist the higher layers in the technology stack, and in particular the User Interface
- Self-documentation of the database
- Graft into graph database some of the semantic functionality that some people turn to RDF for. However, carving out a new path
rather than attempting to emulate RDF!
A Schema layer, as used in the BrainAnnex open-source project, is a software library (called "GraphSchema") that sits between the data and the higher layers.
It's optional, and may be used in a "strict" manner (as an enforcer) or in "lax/loose" manner (data's self-documentation, and assistance to the UI, but no enforcement.)
In essense, a Schema represents what is either expected, or permitted, in our database.
Example
Let's jump into a simple example of some data nodes, and their corresponding Schema nodes:
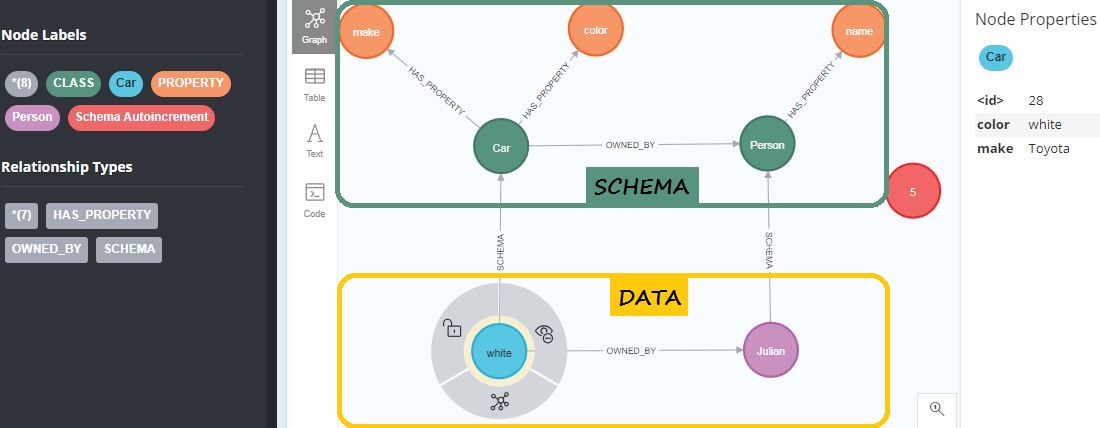
In this example, our data consists of just 2 records, each stored as a graph-database node, in the yellow box at the bottom.
The two records represent, respectively, two entities named "Car" (pale-blue circle) and "Person" (violet circle).
The "Car" entity is expected to have (up to) 2 properties (aka attributes, or fields): "make" and "color".
The "Person" entity is expected to have a single property, "name".
Data summary: a white Toyota is owned by someone named Julian.
The Schema layer (green box at the top) just encapsulates the state of affairs described in the figure's caption, above. Several design specifications can be immediately observed:
- The Schema layer makes use of nodes labeled "CLASS", "PROPERTY" or (less used and not shown in above example) "LINK"
- We'll refer to nodes with the actual data as "Data Nodes" (e.g. those in the yellow box at the bottom),
while nodes reserved for internal use by the Schema layer will be called "Schema Nodes" (e.g. those in the green box at the top)
- The only connection between the "Data" and the "Schema" layers are properties named `_CLASS` that conceptually link
from a Data node to its Schema node (shown as a SCHEMA" relationship in the above diagram, but changed in a recent release; see note below)
- Each "Data Node" may only have a single "Schema Node" Class that describes it. You may think of that Class name as the "type" of that Data Node.
- Schema nodes labeled "CLASS" (green) have relationships among themselves that exactly reflect the (permitted or expected) relationships among the data nodes of those Classes (in our example, "OWNED_BY")
- Nodes in the graph database that lack a `_CLASS` property " to a "CLASS" node, will be un-recognized (ignored) by the Schema
- "Data Nodes" normally contain a label with the same name as their Schema Class; however, this label is treated as secondary,
for convenience and for indexing/constraints. What primarily determines the Schema inclusion
are the `_CLASS` properties of the "Data Nodes"
- "Data Nodes" are free to contain any other label. (Remember, in graph databases such as Neo4j, nodes may have multiple labels, often used for indexing)
IMPORTANT CHANGE: as of version 5 Release Candidates 6, the former `SCHEMA` relationships from Data nodes to Class nodes are now replaced
by `_CLASS` properties (fields) on the Data nodes. But, conceptually, those properties represent relationships to their respective Class nodes.
The main reason to jettison the former `SCHEMA` relationships was to avoid the increased burden of traversing the databases while avoiding generally-meaningless
side paths going from Data nodes to Schema nodes and back to Data nodes.
Freedom of Choice
Even though a main use of the Schema layer is to impose "discipline" (data conformance/integrity), nonetheless freedom of choice is a foundational underpinning of the GraphSchema library. For instance:
- The database may opt to keep some or all nodes out of control of the Schema layer. Anything that lacks a `_CLASS` property to a "CLASS" node, is regarded an "un-managed" node
(with the extensive freedom that is typical in graph databases)
- Want to jettison the Schema layer? Just delete all its nodes ("CLASS", "PROPERTY", "LINK"), and your data will remain un-affected – simply no longer managed by a Schema layer
However, note that if you're also using the higher layers of the BrainAnnex technology stack, those layers assume the presence of a Schema layer; you'll have to provide your own Data Manager, Web API, UI or whatever else
you need. The lower layer, NeoAccess won't be affected.
Services Provided by the Schema Layer
- Methods to define and edit the Schema
- Methods to create, retrieve and delete Data nodes
- A variety of data-import methods, in particular to import Pandas data frames (typically created by reading in CSV files) and to import JSON files (with arbitrary complex structures)
- Optional data-integrity checks during import
- A method to export the entire Schema (as a JSON file)
- Advise the UI about data types, and other hints for the front-end display
- Management of optional URI's (to be precise, parts of the URI's, more technically called "tokens"), with auto-increments in user-specified namespaces
Technical Details
"CLASS" nodes:
- "Class" nodes capture the abstraction of entities that share similarities.
Example: "car", "star", "protein", "patient"
In RDFS lingo, a "Class" node is the counterpart of a resource (entity)
whose "rdf:type" property has the value "rdfs:Class"
- Class can be of the "S" (Strict) or "L" (Lenient) type.
A "lenient" Class will accept data nodes with any properties, whether declared in the Schema or not;
by contrast, a "strict" Class will prevent data nodes to contain properties not declared in the Schema
- Class nodes may be defined not to accept Data nodes attached to them. Typically used for organizing the ontology of the Schema.
- Class nodes have relationships among themselves that exactly reflect the (permitted or expected) relationships among the data nodes of those Classes
- A special relationship named "INSTANCE_OF" may exist between any two Class node. The "child" Class (the one that is an "instance of" another Class) is regarded to possess the Properties of the other Class,
in addition to its own
"PROPERTY" nodes:
- Each "Property" node is linked to exactly one "Class" node, by means of a relationship named "HAS_PROPERTY", in the direction from the Class to the Property node
- The "Property" nodes linked to a given "Class" node represent the attributes (fields) of the Data nodes of that Class
- If the Class is "lax" (not strict) then the Data nodes may also have other attributes not declared in the Schema
"LINK" nodes:
- If any relationship between Class nodes is meant to have properties, that relationship is split in two part,
with an intervening node labeled "LINK" [newly-added feature not fully implemented]
Data nodes:
- Nodes in the graph databases are regarded as "Data nodes" if they possess a property called `_CLASS`, whose value is the name of Class node. (Conceptually,
pointing to a Class node)
- Typically, Data nodes contain a database label with the same name as the schema Class they are attached to, in addition to any other label they might contain;
however, that's NOT consistently enforced by the Schema layer, and is regarded as secondary and (often) optional, though highly recommended
- Labels in Data nodes are in particular used for indexing (fast searching), and to enforce uniqueness constraints.
Keywords used by the Schema layer:
- For node labels: "CLASS", "PROPERTY", "LINK"
- For Class node attributes: "name", "uri", "code", "strict", "no_datanodes"
- For Property and Link node attributes: "name", "uri"
- For relationships names: "HAS_PROPERTY", "INSTANCE_OF"
Typical attributes stored on Property nodes (currently, as a service for the Schema clients, i.e. the higher layers, but NOT managed by the Schema)
- "dtype" (taking values such as "int", "float", "categorical" – for now, at the discretion of the Schema clients)
- "allowed" (only applicable when "dtype" is "categorical"; example, for German articles: ["der","die","das"])
Schema-Layer Relationships
HAS_PROPERTY
Used to connect Class Nodes to any number of Property Nodes.
Note that Property Nodes cannot be linked to more that 1 Class Node. If multiple Classes happen to have Properties with overlapping names, separate Property Nodes are used.
INSTANCE_OF
The INSTANCE_OF relationship between classes offers a way to "factor out" common Properties that occur in multiple Classes.
For example, imagine that your Class "German Vocabulary" contains the Properties "German", "English", "Notes"; and, similarly, your Class
"French Vocabulary" contains the Properties "French", "English", "Notes".
The "English" and "Notes" Properties aren't really specific to either German or French. They more logically belong to a new Class named "Foreign Vocabulary",
of which "German Vocabulary" and "French Vocabulary" are instances of. A clean ontology!
Note that Data Node of a particular Class are allowed to store Properties (aka fields or attributes) that are registered with an "ancestor" (based on the INSTANCE_OF) of their Schema Class.
For example, if you have a Data Node in your database that is associated (by means of a `_CLASS` property) to the Schema Class "French Vocabulary", then you can store in it
values for "French", "English", and "Notes". That's typically more convenient than having to split the Data Node into two (one with the "French" value and one with the "English" and "Notes" values).
Making operations convenient for the higher layers (i.e. the clients of the NeoAccess library) is a foundational design philosophy.